유저가 컴퓨터를 편하게 사용할 수 있게 모든 하드웨어를 관리해주는 프로그램
운영체제를 통해 안정적이고, 효율적인 동작을 하기 위해서는 사용자 또는 응용프로그램이 직접 하드웨어에 접근하는 것을 막아야 한다.
이 때문에 User Mode(CPU 명령어 사용을 제한)와 Kernel Mode(CPU 명령어를 사용해 하드웨어를 직접 제어)로 분리해 운영체제를 사용
User Mode와 Kernel Mode 사이는 System Call and Interrupt을 통해서 전환된다.
입출력, 메모리할당, 프로세스의 생성 등을 수행하는 코드의 집합.
운영체제는 데스크탑 뿐만 아니라 임베디드, 서버, 모바일 등의 기기에서도 사용됨
대표적인 OS의 예시로는 Windows, Unix, macOS, Android 등이 있다.
job이나 task라고도 불리며 PCB(Process Control Block)이라는 걸로 Process들을 관리함
각각의 process는 Process Control Block(PCB)에 관련된 정보를 저장한다.
PCB에서 다루는 Process 정보
parent process에서 child process를 생성
process들은 고유한 process identifier(pid)를 통해 구분, 관리 됨
생성 시 child process는 부모의 PCB를 공유 받으며 어떤 정보를 공유할지는 공유 옵션에 따라 달라짐Resource sharing option(Full/Partial/No sharing) Execution option(Overlay/Swapping) Address space option(Fixed/Variable)
exit system call을 통해 process를 삭제할 수 있다.
present process는 wait system call를 통해 child가 정상적으로 제거되었는지 확인
이 때 제대로 process가 제거되지 않으면 Zombie/Orphan 상태의 process가 만들어진다.Zombie process: parent에서 child가 죽은걸 모르고 process table에 child에 대한 정보가 남아있는 경우 Orphan: child가 terminate되기 전에 parent가 죽어버려서 부모가 없어진 경우
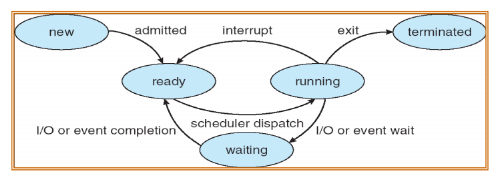
CPU 내부에서 어떤 process를 다음에 실행할지 선택하는 기능 ```
Context switching은 Process가 종료되거나 Scheduling에 의해서 종료될 때 발생
이전의 process 상태를 저장하고 새로운 프로세스의 PCB를 가져오는 역할
Overhead가 심함
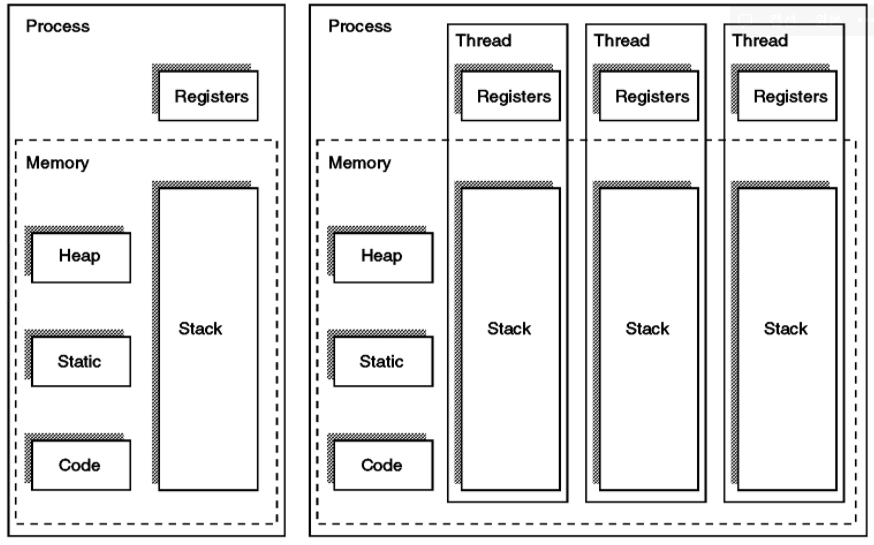
flow of control whitin a process(process와 subprocess로 이해할 수 있음)
각각의 thread는 각자의 register state와 stack을 가지고 있다.
CPU scheduling의 기본 단위process는 프로세스 간의 전환에 대하여 PCB에 접근해서 Process address space를 복사해오는 등의 과정 때문에 overhead가 클 수 밖에 없는데, Thread는 Process에 비해 creation과 switching에 드는 시간이 적다는 장점이 있다. (Memory와 CPU 효율성 면에서 모두 장점을 가짐)
하나의 process에 대해서 여러 thread가 만들어질 수 있고, 이 때 code와 address space, operating resources를 공유한다.
멀티쓰레딩을 통해서 동시성을 추구한다.
병렬성(parallelism) : 여러 코어에서 동시에 process가 처리될 때 [ = num of CPUs(cores) ]
동시성(concurrency) : illusion of parallelism
Process Scheduling을 통해서 CPU 효율성을 최대화할 수 있다.
Scheduling은 process의 상태가 바뀔 때 일어나고 처리할 process는 ready queue와 device queue에 저장되어 관리된다.단일프로세서는 하나의 running process를 가질 수 있기 때문에 더 많은 process가 존재한다면 각각은 CPU에서 실행중인 process가 종료되거나 rescheduled 될 때까지 기다려야한다. 이 때 필요할 것이 process scheduling이다.
CPU utilization과 Throughput을 최대화하고, turnaround time과 waiting time, response time을 최소화하는 것이 중요하다.
수행시간이 긴 프로세스가 자원을 점유하게 되면 이후 실행되어야 하는 프로세스들이 자원을 할당받지 못하는 기아 현상이 발생
프로세스의 우선 순위에 따라 스케쥴링을 하게 되므로 우선순위가 낮은 프로세스는 기아 상태에 빠짐
| 비선점형 | 선점형 |
|---|---|
| 정해진 시간 없이process 종료 전까지 점유 | 일정 시간을 process에 할당해 해당 시간만 자원을 사용하고 반납 |
| 중간에 interupt가 일어나지 않음 | interupt를 통해 실행 중인 process를 교체 |
| 종료 후 context switch 외에 추가적인 오버헤드 없음 | context switch 가 일정 시간마다 일어나기 때문에 오버헤드 있음 |
| 프로세스 우선순위 고려 없음 | 프로세스에 대한 우선순위를 고려 |
| FCFS, SJF, Priority Scheduling | Round-Robin, Multilevel Queue Scheduling |
먼저 도착한 프로세스를 먼저 실행하고, 프로세스가 도착한 순서대로 CPU를 할당한다.
보편적으로 프로세스들의 평균 대기 시간이 길어진다는 문제가 있다.
다음에 실행할 프로세스를 선택할 때 실행 시간이 가장 짧을 것으로 예상되는 프로세스를 선택하는 방식.
이 경우 FCFS보다 평균 대기 시간이 줄어들지만 CPU burst time이 긴 프로세스의 경우 오히려 대기시간이 증가하고 심할 경우 starvation 상태가 되는 문제점이 있다.
각 프로세스에 차례로 일정한 시간 할당량(time quantum) 동안 CPU 자원을 차지할 수 있도록 함.
time quantum 시간이 길다면 FCFS와 같은 형태로 작동하므로 RR 스케줄링을 사용하는 의미가 줄어들고, 시간이 너무 짧다면 너무 많은 Overhead가 생기기 때문에 좋지 않다.
따라서 적절한 time quantum 길이를 찾는 것이 중요함.
Memory : 메인 메모리 RAM(Random Access Memory)을 말하며, 프로그램 실행 시 정보들을 저장하고 가져다 사용할 수 있게 만드는 공간
Physical address vs. Logical address
Physical address : 프로세스가 실행되면서 메모리 내부에 실제로 프로세스가 위치해 있는 주소를 의미 물리적 주소의 경우 항상 그 주소가 비어있을것이라는 보장이 없고, 이미 메모리에 프로그램이 올라가 있으면 문제가 발생 이를 해결하기 위해서 나온 것이 Logical address Logical address : 가상 주소라고도 하며, 물리적 주소와 논리적 주소를 잘 매핑하는 것이 중요하다.Address binding : 논리적 주소에 데이터를 저장해둔 뒤 데이터를 메모리에 로딩할 때나 프로세스를 실행할 때 물리적 주소에 직접 매핑하는 방법
이러한 매핑은 MMU(Memory Management Unit)에서 수행하며, 보통 물리적 주소가 시작하는 base 주소를 논리적 주소에 더해서 데이터를 메모리에 올린다.
Load time binding : 데이터를 메모리에 로딩할 때 논리 주소를 물리 주소에 매핑하는 방식이 방식은 overhead가 너무 심해 요즘은 잘 사용하지 않고,
프로세스를 실행할 때 데이터를 메모리에 올리는 Execution time binding 방식이 주로 쓰인다.
logical address 가 연속적이라면 physical address도 연속적으로 배치하는 것을 의미
이 경우 MMU가 실행 시간 바인딩에서 해야하는 연산이 적다는 장점이 있다.
또한 Memory Protection의 구현이 쉽다.Memory Protection : 시스템에서 참고하는 메모리 주소가 참고 가능한 범위를 넘어서는지를 체크하는 것연속 메모리 할당에서 메모리 공간을 분배하는 방법
- Two Partition Allocation : Kernel과 User 모드 두 부분으로 메모리를 분할하여 활동하는 방식
메모리 공간이 두 개의 파티션으로 분할되기 때문에, 메모리 공간의 낭비가 발생할 수 있다.- Multiple Partition Allocation
Fixed Size Partition : 메모리 공간을 고정 크기로 나누어 사용하는 메모리 관리 방식 > 프로세스가 필요로 하는 메모리 공간의 크기에 따라 파티션을 선택할 수 없기 때문에 내부 단편화가 발생할 가능성이 높음 Variable-size Partition : 메모리 공간을 프로세스의 요구에 따라 가변적으로 할당하는 메모리 관리 방식 > 내부 단편화 문제를 완화시킬 수 있으나 파티션의 크기가 자주 변하기 때문에 메모리 할당 및 해제 과정이 복잡해지고, 외부 단편화 문제가 발생할 가능성이 높음연속 메모리 할당 방식에서는 fragmentation(단편화) 의 문제가 발생하게 된다는 큰 문제가 있어 잘 쓰이지 않는다
외부 단편화: 메모리 내에 충분한 크기의 공간이 있더라도 연속적인 공간이 부족하여 메모리 할당이 불가능한 경우 내부 단편화: 메모리 공간을 할당할 때, 필요한 공간보다 큰 크기의 공간을 할당하여 할당된 메모리에 사용하지 못하는 부분이 발생하는 경우
컴퓨터에는 다양한 파일들이 저장장치에 저장이 된다.
이 떄 운영체제가 저장장치에 있는 데이터를 효율적으로 CRUD 할 수 있는 것을 File System이라 한다.
Name, Type, Location, Size, Timestamps
Identifier : system이 사용하는 유니크한 값
Protection : 접근 권한에 관련된 정보
User identification : 생성, 수정자에 대한 정보
CRUD
Reposition : 열여있는 현재 파일의 탐색을 위한 값
Truncation : 파일을 자르는 개념
Open, Close
Sequential File Structure : 순차적으로 이루어진 파일 구조이며, 불러오는 속도가 빠르며, 작성과 삭제를 하는 구조에서 오래걸리는 단점이 존재
Index File Structure : Sequential 구조에 기반을 두고 있지만, 위치를 잡기위한 index가 첨가되어 있다.[DB와 같이 빠른 접근이 필요할 때 적절]
Direct File Structure : 불연속 구조를 가지며, 물리적으로 위치를 옮겨가며 파일을 관리.[Hashing 함수를 이용하여 물리적 주소를 접근]
Open Operation을 통하여 File을 열면 반환이 되는 포인터를 가지는 인덱스 값
Create, Delete, Search
List : Directory 내부의 Directory or File을 list화 하여 관리
Rename
Traverse : 백업과 같이 다른 장치로 이동할 수 있다.
파일 시스템에서 데이터를 저장하게 될 때 할당되는 방식
디스크에 연속적으로 블록이 할당이 되는 방식 -> 매우 빠른 동작을 하게 된다.
하지만 할당 할 수 있는 영역이 부족한 상태에서는 할당하지 못하고 영역이 남는 조각화가 발생할 수 있다.
불연속으로 할당을 하는 방식, 비어있는 블록에 데이터를 분산하여 저장하는 방식
Linked Allocation : 각 블록에 다음 블록의 위치를 저장하여 파일을 이어주는 방식[조각화 문제를 해결할 수 있다.] --> 하지만 연결된 마지막 파일을 사용할때 속도가 느려질 수 있다. Index Allocation : 인덱스 블록을 사용하여 모든 파일 블록의 위치를 저장하는 방식
초기에 사용하던 방식이며 윈도우에서 대부분 호한이 잘 된다.
파일을 작은 클러스터로 나누어서 관리하며 최대용량이 작은 편이다.
암호화, 압축이 지원되지 않으며, 조각화와 단편화가 발생하기 쉽다.
FAT의 한계를 개선한 고급 파일 시스템으로, 파일 암호화, 압축, 파일 복구 등 다양한 기능을 지원
리눅스 기반 운영체제에서 사용하는 파일 시스템
Journaling : 데이터 변경사항 발생시 로그에 기록 -> 문제가 발생하게 되면 로그를 기반으로 하여 복구를 할 수 있게 지원
Journaling 기능을 추가해 데이터 안정성을 강화하였으며, 대용량 파일 및 파티션을 지원
Apple의 최신 파일 시스템으로, SSD 최적화, 스냅샷 기능, 파일 및 디렉토리 복제 성능 향상을 지원
DataBase System [ 2024년12월13일 ]
Operating System Concepts [ 2024년12월11일 ]